 云成本分析
云成本分析 自动定量应用程序
自动定量应用程序 亚马逊网络服务
亚马逊网络服务 大数据
大数据 容器的基础设施
容器的基础设施 雷竞技地址ray
雷竞技地址ray 预留的容量管理
预留的容量管理 云服务的议员
云服务的议员 谷歌云平台
谷歌云平台 关于NetApp
关于NetApp Elastigroup
Elastigroup 海洋
海洋 海洋CD
海洋CD 现场存储
现场存储 生态
生态 CloudCheckr
CloudCheckr 雷竞技官方网站
雷竞技官方网站 现场安全
现场安全 雷竞技苹果app官方版下载
雷竞技苹果app官方版下载 资源中心
资源中心 文档
文档 新闻
新闻 服务状态
服务状态 CloudOps中心
CloudOps中心 我们的故事
我们的故事 现场团队
现场团队 联系我们
联系我们 我们的价值观
我们的价值观
 阅读时间:8分钟
阅读时间:8分钟
Elasticsearch是一个强大的分布式搜索和分析引擎设计的可伸缩性、可靠性和易于管理。Elasticsearch运行时它可以轻松升级当你考虑成本所需的处理和内存Elasticsearch节点。让我们穿过如何运行节点现场安全EC2实例使用Spotinst Elastigroup服务。本教程我将使用我们的新热EBS迁移特性。热EBS迁移将允许您创建一个EBS卷池,Elastigroup动态连接到实例。热EBS迁移支持点和需求实例和有多个可用性区域。
我将使用弹性。公司博客上配置一个Elasticsearch集群AWS供参考:https://www.elastic.co/blog/running-elasticsearch-on-aws
主节点
- 在EC2控制台提供一个新实例使用亚马逊最新的Linux AMI(稍后写下的AMI ID)。

- 选择M4.2xlarge作为实例类型
- 我建议使用AWS实例细节SSM例如管理。如果你没有一个我的角色对舰导弹可以轻松地创建一个遵循本指南。http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/systems-manager.html
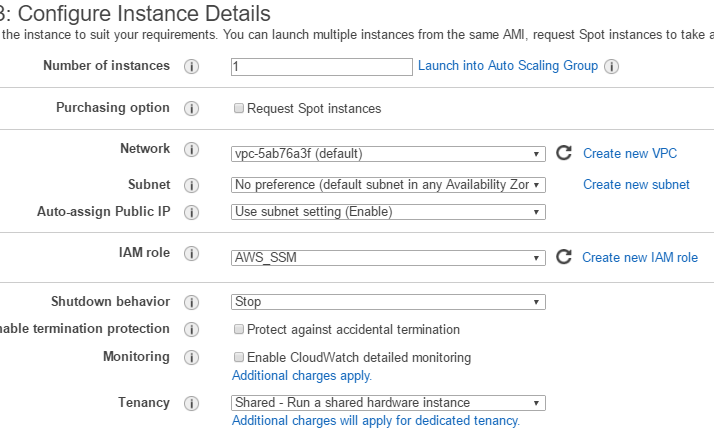
- 点击高级细节并输入以下用户数据脚本如下你所看到的。这个脚本将安装有关SSM代理(可选),山ebs卷和安装/配置Elasticsearch包。
# !/bin/bash cd / tmp curl https://amazon ssm -我们-西方- 2. - s3.amazonaws.com/latest/linux_amd64/amazon ssm - agent.rpm - o amazon-ssm-agent。rpm yum安装- y amazon-ssm-agent。rpm sudo mkdir /媒体/ elasticsearchvolume #确定实例id和实例生命周期通过aws cli命令INSTANCEID = " $ (curl http://169.254.169.254/latest/meta-data/instance-id) "出口AWS_DEFAULT_REGION = us-west-2架= " (aws ec2举例描述——实例id INSTANCEID美元——查询预订[0].Instances [*]。[InstanceLifecycle]”——输出文本)sudo mkfs -t /dev/xvdb sudo mount /dev/xvdb /media/elasticsearchvolume/ sudo sh -c "echo '/dev/xvdb /media/elasticsearchvolume ext4 defaults,nofail 0 0' >> /etc/fstab" sudo rpm -i https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.3/elasticsearch-2.3.3.rpm sleep 2 sudo chown elasticsearch: /media/elasticsearchvolume sudo chkconfig --add elasticsearch sleep 2 cd /usr/share/elasticsearch/ yes | sudo bin/plugin install cloud-aws sleep 2 sudo sh -c "echo 'ES_HEAP_SIZE=10g' >> /etc/sysconfig/elasticsearch" sudo sh -c "echo 'MAX_LOCKED_MEMORY=unlimited' >> /etc/sysconfig/elasticsearch" PRIVATEIP="$(curl http://instance-data/latest/meta-data/local-ipv4)" sudo sh -c "echo 'cluster.name : esonaws' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'bootstrap.mlockall : true' >> /etc/elasticsearch/elasticsearch.yml" sleep 2 sudo sh -c "echo 'discovery.zen.ping.unicast.hosts : [\""$PRIVATEIP"\"]' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'network.host : [\"127.0.0.1\",\""$PRIVATEIP"\"]' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'path.data : /media/elasticsearchvolume' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'node.rack_id : "$RACK"' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'cluster.routing.allocation.awareness.attributes: rack_id' >> /etc/elasticsearch/elasticsearch.yml" sudo chown elasticsearch: /media/elasticsearchvolume sudo service elasticsearch start Sleep 2
- 为您的数据添加一个新的卷。我用/dev/sdb和23 gb GP2体积但你可以定制这个在你认为合适的地方。

- 主节点添加一个描述性的名称标签。
- 创建一个新的安全组,允许TCP 9200和TCP 9300内部交通和SSH外部管理。

- 启动您的实例和SSH到实例一旦启动并运行。
- 使用curl来一个API请求检查你新主人的地位。您应该看到一个“绿色”的地位如下你所看到的。参考Elasticsearch博客的更多信息:https://www.elastic.co/blog/running-elasticsearch-on-aws
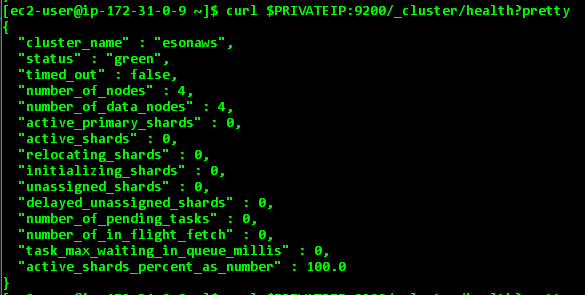
- 使注意主您刚刚创建的私有ip使用后,创建Elasticsearch节点。





碎片分配意识
如果Elasticsearch意识到的物理配置你的服务器,它可以确保主碎片和复制碎片分布在不同的物理服务器、机架、或区域,以最大限度地降低风险同时失去所有碎片的副本。在我们的例子中,我们将需要定义2逻辑架:一个将按需和其他。如果你仔细观察用户数据脚本,您将看到,我们使用AWS CLI确定这个信息。我们也更新elasticsearch。yml相应配置文件在每个服务器上。建议您改变当地配置像架通过elasticserach id。yml文件通过api和集群配置。
当启动一个实例时,我们意识到启动脚本实例的生命周期(现货或按需),并将相应的分配架id。
热EBS迁移
在我们进入创建Elasticsearch节点集群,可以首先创建EBS卷,我们将使用数据存储。
- 打开EC2控制台,点击“卷”
- 让我们创建四个GP2卷。选择你喜欢的尺寸在直布罗陀海峡和单击create
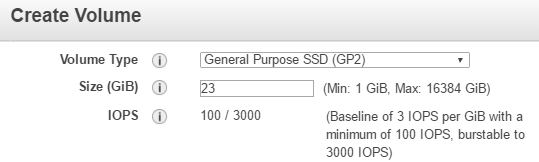
- 复制您刚才创建的卷的卷id后来到一个文本编辑器。

创建Elasticsearch Elastigroup集群
- Elastigroups打开Spotinst控制台和浏览。点击“创建”按钮以启动向导。
- Elasticsearch集群输入一个描述性的名称,选择同一地区作为您在前面创建的主节点。
- 改变集群50%点,选择100秒作为排水超时,并设定你的目标/最小/最大3。
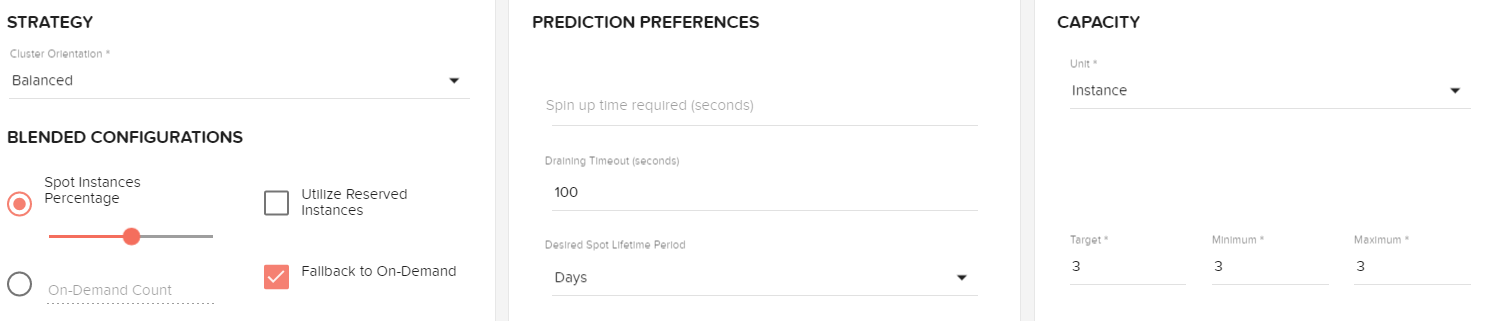
- 在计算页面,选择相同的VPC和AMI id用于你的主人。

- 选择三个可用性区域并选择m3.2xlarge m4.2xlarge, m4.4xlarge。市场的得分应该改变如下(得分会有所不同)。
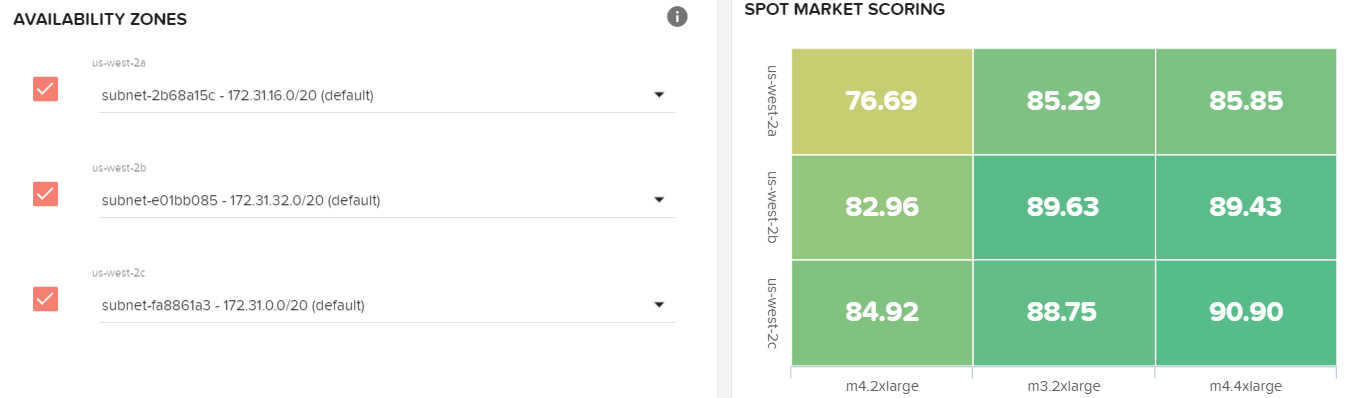
- 如果您使用的是导弹确保使用前面创建的导弹的作用。您可以使用相同的密钥对你的主人如果你喜欢这里。
- 下热EBS迁移、复制和粘贴您在前面创建的EBS卷id。按标签粘贴后每个id id应该成为选择如下你所看到的。
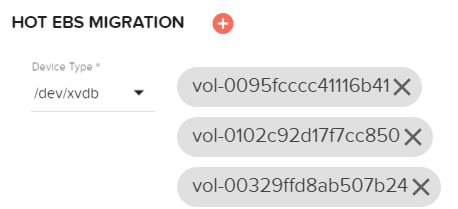
- 以下用户数据脚本复制并粘贴到下面的用户数据部分。此脚本将安装Elasticsearch,山EBS数据量,并配置Elasticsearch服务。一定要更新主的私有ip如下表示。注意,一定要更新你的Elastigroup配置和删除线格式的数据量。更新Elastigroup后一卷不是必需的。
# !/bin/bash cd / tmp curl https://amazon ssm -我们-西方- 2. - s3.amazonaws.com/latest/linux_amd64/amazon ssm - agent.rpm - o amazon-ssm-agent。rpm yum安装- y amazon-ssm-agent。rpm sudo mkdir /媒体/ elasticsearchvolume #确定实例id和实例生命周期通过aws cli命令INSTANCEID = " $ (curl http://169.254.169.254/latest/meta-data/instance-id) "出口AWS_DEFAULT_REGION = us-west-2架= " (aws ec2举例描述——实例id INSTANCEID美元——查询预订[0].Instances [*]。[InstanceLifecycle]”——输出文本)#BE SURE TO REMOVE THE LINE BELOW AFTER INITIAL DEPLOYMENT TO ENSURE DATA VOLUME IS NOT WIPED sudo mkfs -t /dev/xvdb sudo mount /dev/xvdb /media/elasticsearchvolume/ sudo sh -c "echo '/dev/xvdb /media/elasticsearchvolume ext4 defaults,nofail 0 0' >> /etc/fstab" sudo rpm -i https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.3.3/elasticsearch-2.3.3.rpm sleep 2 sudo chown elasticsearch: /media/elasticsearchvolume sudo chkconfig --add elasticsearch sleep 2 cd /usr/share/elasticsearch/ yes | sudo bin/plugin install cloud-aws sleep 2 sudo sh -c "echo 'ES_HEAP_SIZE=10g' >> /etc/sysconfig/elasticsearch" sudo sh -c "echo 'MAX_LOCKED_MEMORY=unlimited' >> /etc/sysconfig/elasticsearch" PRIVATEIP="$(curl http://instance-data/latest/meta-data/local-ipv4)" sudo sh -c "echo 'cluster.name : esonaws' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'bootstrap.mlockall : true' >> /etc/elasticsearch/elasticsearch.yml" sleep 2 # You will need to type in the private ip of your Master node below sudo sh -c "echo 'discovery.zen.ping.unicast.hosts : [\"IP ADDRESS OF MASTER NODE ABOVE\"]' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'network.host : [\"127.0.0.1\",\""$PRIVATEIP"\"]' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'path.data : /media/elasticsearchvolume' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'node.rack_id : "$RACK"' >> /etc/elasticsearch/elasticsearch.yml" sudo sh -c "echo 'cluster.routing.allocation.awareness.attributes: rack_id' >> /etc/elasticsearch/elasticsearch.yml" sudo chown elasticsearch: /media/elasticsearchvolume sudo service elasticsearch start Sleep 2
- 为你添加一个名称标签实例标记部分。

- 在底部,单击next去扩展页面。
- 因为我们这里不使用扩展政策,允许再次单击next和查看json输出。单击Create按钮在右下角,当准备好了。





运行Elasticsearch
现在我们已经安装和配置的一切让我们确保Elasticsearch启动并运行和我们的新节点是健康的。让我们运行相同的API请求早些时候来检查我们的集群的状态。您现在应该看到四个数据节点(一个主和三个节点启动了Elastigroup)。
你可以看到我们在Elasticsearch还没有任何数据,因为我们没有任何碎片。让我们加载示例数据集将文档数到1000。
wget https://github.com/elastic/elasticsearch/blob/master/docs/src/test/雷竞技rabet官网resources/accounts.json?生= trueasdf - o账户。json curl -XPOST ' localhost: 9200 /银行/账户/ _bulk吗?pretty&refresh”——data-binary @accounts。json“旋度localhost: 9200 / _cat /指数? v '
![]()
好,现在我们有一些文档,让我们再次检查碎片的数量。

太好了,我们现在有一些数据加载,我们有5个主碎片和5副本中的死亡总人数达到10活跃的碎片。因为我们有四个数据节点让我们添加一个额外的副本“银行”指数通过API。
旋度-XPUT ' localhost: 9200 /银行/ _settings ' - d ' {“number_of_replicas”: 2} '
正如您将在下面看到的,我们现在有5个主碎片和十个副本中的死亡总人数达到15活跃的碎片。
我们现在有一个完全冗余Elasticsearch集群运行在50%点和50%的混合需求实例!的任何硬件故障或中断你可以放心,Elastigroup将自动将现有的EBS卷附加到新实例自动为你。
故障转移测试
现在让我们从集群中删除一个实例模拟中断。进入你Elastigroup配置从控制台和集群分离现货实例之一。
如果我们运行一个API调用向集群中我们可以看到,我们已经失去了我们的一些复制碎片由于现场干扰。

现在让我们等待更换现场实例来生活。的启动脚本中定义的用户数据将自动安装和配置服务器。由于我们使用热EBS迁移,数据量将自动连接到新实例。一旦更换实例启动并运行我们可以再次查询API集群的状态。

现在更换现货实例启动并运行我们可以看到副本节点备份和运行感谢我们热EBS迁移功能和引导配置,我们创建了用户数据!
结论
我们希望你喜欢这个教程如何开始使用现货实例上安全地Elasticsearch集群。这是一个基本的例子,但您可以很容易地适用于这里的想法和创建一个更大、更复杂的集群而攒钱在你的EC2花用Spotinst服务。